पी-मान का उपयोग एक्सेल में सह-संबंध और प्रतिगमन विश्लेषण में किया जाता है जो हमें यह पहचानने में मदद करता है कि प्राप्त किया गया परिणाम संभव है या नहीं और परिणाम से काम करने के लिए कौन सा डेटा 0 से 1 तक पी-वैल्यू रेंज के मूल्य के साथ काम करता है, वहाँ एक्सेल में कोई इनबिल्ट तरीका नहीं है कि हम दिए गए डेटा के पी-वैल्यू का पता लगा सकें, इसके बजाय हम अन्य फ़ंक्शन जैसे ची फ़ंक्शन का उपयोग करते हैं।
एक्सेल पी-वैल्यू
पी-मूल्य शून्य परिकल्पना का समर्थन या अस्वीकार करने के लिए परिकल्पना परीक्षण में प्रतिशत मूल्य में व्यक्त की गई संभावना के अलावा कुछ भी नहीं है। P- मान या संभाव्यता मान सांख्यिकीय दुनिया में एक लोकप्रिय अवधारणा है। सभी आकांक्षी विश्लेषकों को डेटा विज्ञान में पी-मूल्य और इसके उद्देश्य के बारे में जानना चाहिए। डेटा बिंदुओं की एक आवृत्ति को परीक्षण परिकल्पना के लिए काल्पनिक आवृत्ति और मनाया महत्व स्तर कहा जाता है।
- P- मान को दशमलव बिंदुओं द्वारा निरूपित किया जाता है, लेकिन दशमलव बिंदुओं के बजाय P- मान के प्रतिशत में परिणाम बताना हमेशा एक अच्छी बात होती है। दशमलव अंक 0.05 बताने से 5% हमेशा बेहतर होता है।
- पी-मूल्य का पता लगाने के लिए किए गए परीक्षण में, यदि पी-मूल्य छोटा है, तो अशक्त परिकल्पना और आपके डेटा के खिलाफ मजबूत सबूत अधिक महत्वपूर्ण या महत्वपूर्ण हैं। यदि पी-मूल्य अधिक है, तो अशक्त परिकल्पना के खिलाफ कमजोर सबूत है। इसलिए, एक परिकल्पना परीक्षण चलाकर और पी-मान प्राप्त करके, हम वास्तव में खोज के महत्व को समझ सकते हैं।

एक्सेल में टी-टेस्ट में पी-वैल्यू की गणना कैसे करें?
एक्सेल टी-टेस्ट में पी वैल्यू की गणना करने के लिए नीचे दिए गए उदाहरण हैं।
पी-वैल्यू एक्सेल टी-टेस्ट उदाहरण # 1
एक्सेल में, हम आसानी से पी-मूल्य पा सकते हैं। एक्सेल में टी-टेस्ट चलाकर, हम वास्तव में इस कथन पर पहुँच सकते हैं कि क्या अशक्त परिकल्पना TRUE है या FALSE है। व्यावहारिक रूप से अवधारणा को समझने के लिए नीचे दिए गए उदाहरण को देखें।
मान लें कि आपको आहार डेटा के माध्यम से वजन घटाने की प्रक्रिया के साथ आपूर्ति की जाती है, और नीचे आपको परिकल्पना का परीक्षण करने के लिए डेटा उपलब्ध है।

चरण 1: पहली चीज जो हमें करने की ज़रूरत है वह आहार से पहले और आहार के बाद के बीच के अंतर की गणना करना है।
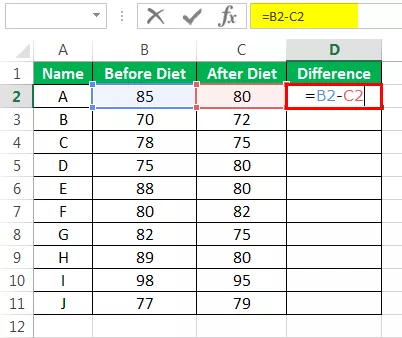
आउटपुट नीचे दिया गया है:

फॉर्मूला को बाकी कोशिकाओं तक खींचें।

चरण 2: अब डेटा टैब पर जाएं, और डेटा के नीचे, टैब डेटा विश्लेषण पर क्लिक करें।

चरण 3: अब नीचे स्क्रॉल करें और खोजें T.Test: Paired Two Sample for Means।

चरण 4: अब आहार कॉलम से पहले चर 1 रेंज का चयन करें।

चरण 5: चर 2 एक आहार स्तंभ के बाद की तरह है।

चरण 6: अल्फा मान 0.05 डिफ़ॉल्ट होगा, अर्थात, 5%। उसी मूल्य को बनाए रखने के लिए।
नोट: 0.05 और 0.01 अक्सर सामान्य स्तर के महत्व के होते हैं।

चरण 7: अब आउटपुट रेंज का चयन करें, अर्थात, जहाँ आप अपने विश्लेषण परिणाम प्रदर्शित करना चाहते हैं।

स्टेप 8: ओके पर क्लिक करें। हमारे पास सेल एफ 1 से विश्लेषण के परिणाम हैं।
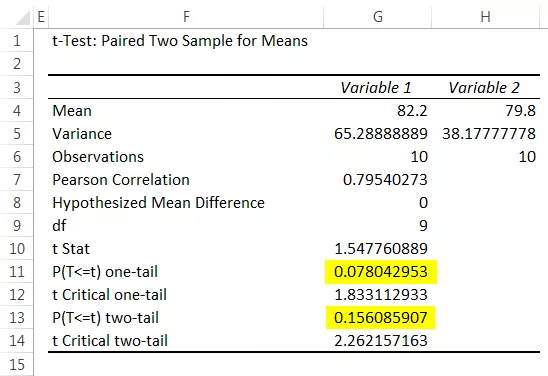
ठीक है, हमारे यहाँ परिणाम हैं। एक-पूंछ परीक्षण के साथ पी-मूल्य 0.078043 है, और दो पूंछ परीक्षणों के साथ पी-मूल्य 0.156086 है। दोनों मामलों में, पी-मूल्य अल्फा मान से अधिक है, अर्थात, 0.05।
इस मामले में, पी-मूल्य अल्फा मान से अधिक है, इसलिए अशक्त परिकल्पना TRUE है, अर्थात अशक्त परिकल्पना के खिलाफ कमजोर साक्ष्य। इसका मतलब है कि वे वास्तव में दो डेटा बिंदुओं के बीच बहुत करीबी डेटा बिंदु हैं।
P-Value Excel उदाहरण # 2 - T.TEST फ़ंक्शन के साथ P- मान ढूँढें
एक्सेल में, हमारे पास T.TEST नामक एक अंतर्निहित फ़ंक्शन होता है, जो हमें तुरंत P-Value परिणाम दे सकता है।
स्प्रेडशीट में किसी भी सेल में T.TEST फ़ंक्शन खोलें।

आहार कॉलम से पहले सरणी 1 का चयन करें।
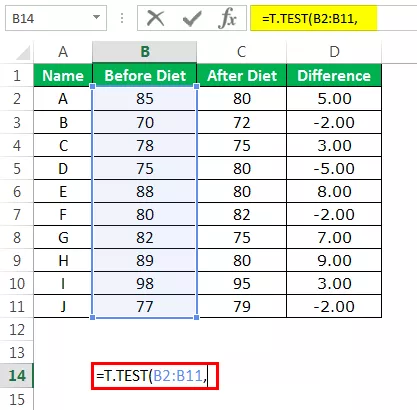
दूसरा तर्क आहार स्तंभ के बाद होगा, अर्थात, सरणी 2

पूंछ एक-पूंछ वितरण होगी।

प्रकार हो जाएगा युग्मित ।

अब सूत्र बंद करें, हमारे पास पी-वैल्यू का परिणाम होगा।

तो, हमारे पास पी-मान है, अर्थात, 0.078043, जो विश्लेषण परिणाम के पिछले परीक्षण के समान है।

याद रखने वाली चीज़ें
- आप विभिन्न स्तरों पर महत्व स्तर (अल्फा मान) को बदल सकते हैं और विभिन्न बिंदुओं पर एक्सेल में पी वैल्यू पर पहुंच सकते हैं।
- सामान्य अल्फा मान 0.05 और 0.01 हैं।
- यदि पी-मान> 0.10 है, तो डेटा महत्वपूर्ण नहीं है; यदि पी-मान <= 0.10 है, तो डेटा थोड़ा महत्वपूर्ण है।
- यदि पी-मान <= 0.05 है, तो डेटा महत्वपूर्ण है, और यदि पी-मान <0.05 है, तो डेटा अत्यधिक महत्वपूर्ण है।








