एक्सेल के साथ ची-स्क्वायर टेस्ट
एक्सेल में ची-स्क्वायर परीक्षण सबसे अधिक इस्तेमाल किया जाने वाला गैर-पैरामीट्रिक परीक्षण है जिसका उपयोग यादृच्छिक रूप से चयनित डेटा के लिए दो या अधिक चर की तुलना में किया जाता है। यह एक प्रकार का परीक्षण है जो दो या दो से अधिक चर के बीच संबंध का पता लगाने के लिए उपयोग किया जाता है, इसका उपयोग उन आँकड़ों में किया जाता है जिन्हें ची-स्क्वायर पी-मूल्य के रूप में भी जाना जाता है, एक्सेल में हमारे पास एक इनबिल्ट फ़ंक्शन नहीं होता है लेकिन हम उपयोग कर सकते हैं ची-स्क्वायर टेस्ट के लिए गणितीय सूत्र का उपयोग करके एक्सेल में ची-स्क्वायर टेस्ट करने के सूत्र।
प्रकार
- फिट की अच्छाई के लिए ची-स्क्वायर परीक्षण
- दो चर की स्वतंत्रता के लिए ची-स्क्वायर परीक्षण।
# 1 - फिट की अच्छाई के लिए ची-स्क्वायर परीक्षण
इसका उपयोग उस नमूने की निकटता का अनुभव करने के लिए किया जाता है जो आबादी के अनुरूप है। ची-स्क्वायर परीक्षण का प्रतीक (2) है। यह सभी ( अवलोकित गणना - प्रत्याशित गणना) 2 / प्रत्याशित गणना का योग है ।
- जहां k-1 डिग्री की स्वतंत्रता या डी.एफ.
- जहां ओआई मनाया आवृत्ति है, के श्रेणी है, और ईआई अपेक्षित आवृत्ति है।
नोट: - एक सांख्यिकीय मॉडल के फिट होने की अच्छाई यह समझने के लिए है कि नमूना डेटा कितनी अच्छी तरह से टिप्पणियों का एक सेट फिट बैठता है।
उपयोग करता है
- उनके आयु समूहों और व्यक्तिगत ऋण के आधार पर उधारकर्ताओं की साख
- सेल्समैन और प्रशिक्षण के प्रदर्शन के बीच संबंध प्राप्त हुआ
- किसी एक शेयर और फ़ार्मास्युटिकल या बैंकिंग जैसे क्षेत्र के शेयरों पर लौटें
- दर्शकों की श्रेणी और एक टीवी अभियान का प्रभाव।
# 2 - दो चर की स्वतंत्रता के लिए ची-स्क्वायर परीक्षण
यह जाँचने के लिए उपयोग किया जाता है कि चर एक दूसरे के स्वायत्त हैं या नहीं। (आर -1) (सी -1) स्वतंत्रता की डिग्री के साथ
जहां ओआई मनाया आवृत्ति है, आर पंक्तियों की संख्या है, सी कॉलम की संख्या है, और ईआई अपेक्षित आवृत्ति है
नोट: - दो रैंडम वैरिएबल को स्वतंत्र कहा जाता है यदि एक वैरिएबल का वितरण दूसरे से प्रभावित न हो।उपयोग करता है
स्वतंत्रता का परीक्षण निम्नलिखित स्थितियों के लिए उपयुक्त है:
- एक श्रेणीगत चर है।
- दो श्रेणीगत चर हैं, और आपको उनके बीच संबंध निर्धारित करने की आवश्यकता होगी।
- क्रॉस-टेब्यूलेशन हैं, और दो श्रेणीबद्ध चर के बीच के संबंध को खोजने की आवश्यकता है।
- गैर-मात्रात्मक चर हैं (उदाहरण के लिए, सवालों के जवाब जैसे, क्या विभिन्न आयु वर्ग के कर्मचारी विभिन्न प्रकार की स्वास्थ्य योजनाएं चुनते हैं)?
एक्सेल में ची-स्क्वायर टेस्ट कैसे करें? (उदाहरण के साथ)
एक रेस्तरां का प्रबंधक ग्राहकों की संतुष्टि और तालिकाओं की प्रतीक्षा कर रहे लोगों के वेतन के बीच संबंध खोजना चाहता है। इसमें हम ची-स्क्वायर का परीक्षण करने की परिकल्पना स्थापित करेंगे
- वह 100 ग्राहकों से एक यादृच्छिक नमूना लेती है जो पूछती है कि क्या सेवा उत्कृष्ट, अच्छी या खराब थी।
- वह तब निम्न, मध्यम और उच्च के रूप में प्रतीक्षा कर रहे लोगों के वेतन को वर्गीकृत करता है।
- मान लीजिए कि महत्व का स्तर 0.05 है। यहाँ, H0 और H1 टेबल की प्रतीक्षा कर रहे लोगों के वेतन पर सेवा की गुणवत्ता की स्वतंत्रता और निर्भरता को दर्शाते हैं।
- एच 0 - सेवा की गुणवत्ता तालिकाओं की प्रतीक्षा कर रहे लोगों के वेतन पर निर्भर नहीं है।
- एच 1 - सेवा की गुणवत्ता तालिकाओं की प्रतीक्षा कर रहे लोगों के वेतन पर निर्भर है।
- उसके निष्कर्ष नीचे दी गई तालिका में दिखाए गए हैं:
इसमें, हमारे पास 9 डेटा बिंदु हैं हमारे पास 3 समूह हैं, जिनमें से प्रत्येक को वेतन के बारे में एक अलग संदेश मिला है, और परिणाम नीचे दिया गया है।

अब हम सभी पंक्तियों और स्तंभों का योग गिनने जा रहे हैं। हम इसे सूत्र की सहायता से करेंगे, अर्थात, SUM। कुल कॉलम में बहुत बढ़िया करने के लिए, हमने = SUM (B4: D4) लिखा है और फिर एंटर कुंजी दबाएं।

यह हमें 26 देगा । हम सभी पंक्तियों और स्तंभों के साथ एक ही प्रदर्शन करेंगे।

स्वतंत्रता की डिग्री (DF) की गणना करने के लिए , हम (r-1) (c-1) का उपयोग करते हैं
DF = (3-1) (3-1) = 2 * 2 = 4
- सेवा की 3 श्रेणियां और वेतन की 3 श्रेणियां हैं।
- हमारे पास मध्यम वेतन (नीचे पंक्ति, मध्य) के साथ 27 उत्तरदाता हैं
- हमारे पास एक अच्छी सेवा के साथ 51 उत्तरदाता हैं (अंतिम कॉलम, मध्य)
अब हमें प्रत्याशित आवृत्तियों की गणना करनी होगी : -
अपेक्षित आवृत्तियों की गणना एक सूत्र का उपयोग करके की जा सकती है: -
- उत्कृष्ट के लिए गणना करने के लिए , हम एन द्वारा विभाजित उत्कृष्ट के कुल के साथ निम्न के कुल को गुणा करेंगे ।
मान लीजिए कि हमें पहली पंक्ति और 1 कॉलम (= B7 * E4 / B9 ) के लिए गणना करनी है । यह उन ग्राहकों की अपेक्षित संख्या देगा, जिन्होंने निम्न, यानी, 8.32 के रूप में प्रतीक्षा कर रहे लोगों के वेतन के लिए उत्कृष्ट सेवा की है ।
- ई 11 = - (32 * 26) / 100 = 8.32 , ई 12 = 7.02 , ई 13 = 10.66
- ई 21 = 16.32 , ई 22 = 13.77 , ई 23 = 20.91
- ई 31 = 7.36 , ई 32 = 6.21 , ई 33 = 9.41
इसी तरह, सभी के लिए, हमें ऐसा ही करना है, और सूत्र नीचे आरेख में लागू किया गया है।

हम नीचे दी गई अपेक्षा के अनुसार अपेक्षित आवृत्ति तालिका प्राप्त करते हैं: -

नोट: - मान लें कि महत्व का स्तर 0.05 है। यहाँ, H0 और H1 टेबल की प्रतीक्षा कर रहे लोगों के वेतन पर सेवा की गुणवत्ता की स्वतंत्रता और निर्भरता को दर्शाते हैं।
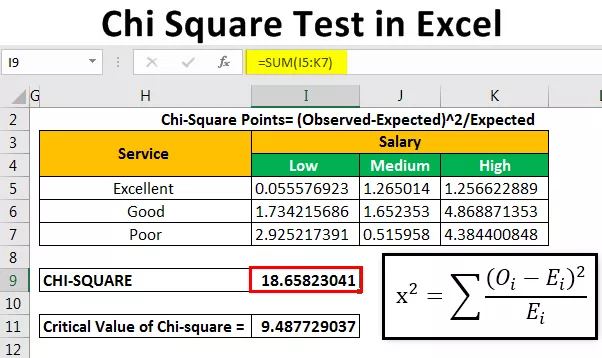
अपेक्षित आवृत्ति की गणना करने के बाद, हम एक सूत्र का उपयोग करके ची-स्क्वायर डेटा बिंदुओं की गणना करेंगे।
ची-स्क्वायर पॉइंट्स = (अवलोकन-प्रत्याशित) 2 / अपेक्षित
पहले बिंदु की गणना करने के लिए, हम = (B4-B14) 2 / B14 लिखते हैं ।

हम मान को स्वचालित रूप से भरने के लिए सूत्र को अन्य कोशिकाओं में कॉपी और पेस्ट करेंगे।

इसके बाद, हम तालिका के ऊपर दिए गए सभी मानों को जोड़कर चि-मान (परिकलित मान) की गणना करेंगे ।

हमें 18.65823 के रूप में ची-मूल्य मिला ।

इसके लिए महत्वपूर्ण मूल्य की गणना करने के लिए, हम एक chi-square महत्वपूर्ण मूल्य तालिका का उपयोग करते हैं, हम नीचे दिए गए सूत्र का उपयोग कर सकते हैं।
इस सूत्र में 2 पैरामीटर CHISQ.INV.RT (संभावना, स्वतंत्रता की डिग्री) शामिल हैं।
संभावना 0.05 है, और यह एक महत्वपूर्ण मूल्य है जो हमें यह निर्धारित करने में मदद करेगा कि नल की परिकल्पना (एच 0 ) को स्वीकार करना है या नहीं।

ची-वर्ग का महत्वपूर्ण मान 9.487729037 है।

अब हम ची-वर्ग या (P-value) = CHITEST (वास्तविक_अनुप्रयोग, अपेक्षित_ व्यवस्था) का मान पाएंगे
रेंज से CHITEST (B4: D6, B14: D16) ।

जैसा कि हमने देखा है, ची-टेस्ट या पी-वैल्यू का मान = 0.00091723 है।

हमने सभी मूल्यों की गणना की है। ची-वर्ग (परिकलित मान) मूल्यों केवल महत्वपूर्ण है, जब इसके मूल्य से अधिक एक ही है या कर रहे हैं महत्वपूर्ण मान 9.48, यानी, महत्वपूर्ण मान (सारणीबद्ध मूल्य) की तुलना में अधिक होना चाहिए 18.65 स्वीकार करने के लिए रिक्त परिकल्पना (एच 0 ) ।
लेकिन यहां पर गणना मूल्य > सारणीबद्ध मूल्य
एक्स 2 (परिकलित)> एक्स 2 (सारणीबद्ध)
18.65> 9.48
इस मामले में, हम अशक्त परिकल्पना (एच 0 ) को अस्वीकार करेंगे , और वैकल्पिक (एच 1 ) स्वीकार किया जाएगा।
- हम पी-वैल्यू का अनुमान लगाने के लिए भी पी-वैल्यू का उपयोग कर सकते हैं, यदि पी-वैल्यू <= α (महत्वपूर्ण मूल्य 0.05), शून्य परिकल्पना को अस्वीकार कर दिया जाएगा।
- यदि पी-मान> α , शून्य परिकल्पना को अस्वीकार नहीं करते हैं ।
यहाँ P-value (0.0009172) < α (0.05), H 0 को अस्वीकार करें , H 1 को स्वीकार करें
उपरोक्त उदाहरण से, हम यह निष्कर्ष निकालते हैं कि सेवा की गुणवत्ता प्रतीक्षा कर रहे लोगों के वेतन पर निर्भर है।
याद रखने वाली चीज़ें
- एक मानक सामान्य चर के वर्ग का ध्यान रखता है।
- यदि विभिन्न श्रेणियों में देखी गई आवृत्तियों का मूल्यांकन मान्यताओं के एक निर्धारित समूह के तहत अपेक्षित आवृत्तियों से काफी भिन्न होता है।
- निर्धारित करता है कि अनुमानित वितरण डेटा को कितनी अच्छी तरह फिट करता है।
- आकस्मिक तालिकाओं का उपयोग करता है (बाजार शोध में, इन तालिकाओं को क्रॉस-टैब कहा जाता है)।
- यह नाममात्र स्तर के माप का समर्थन करता है।








